Pannana is a mobile app that
enables Thai people with visual impairment to enjoy movies and any visual contents by listening to audio
description along with the movie.
Audio description (AD) is an additional narration that describes what
is happening on the screen when there is no dialogue. It depicts the key visual elements that are necessary to
understanding the content on the screen.
In order to create audio descriptions, the staff have to do a few works including;
finding the time code where they should place the audio descriptions (the part of audio that has no dialogue),
interpreting the context of the video and writing one or a few sentences that best describe each scene,
recording the narration of AD, post-processing the sound and exporting the audio file.
The
whole process is quite complicated and requires a lot of time and human effort. Currently, only a few groups of
people are able to create the ADs. As a consequence, the amount of content in the Pannana app is limited and it
is hard to catch up with the current trend.
VOHAN
aims to apply the concept of crowdsourcing to the AD generation process by
letting AI handle the laborious and repetitive tasks. This means the staff can finish the process more quickly,
adding more up-to-date content to the Pannana app. In addition, VOHAN makes writing AD scripts an effortless
task that anyone can easily come and write the descriptions. As a result, more people can participate and help
Pannana grow in order to increase equal access to media, which is the basic right for everyone.
How VOHAN works?
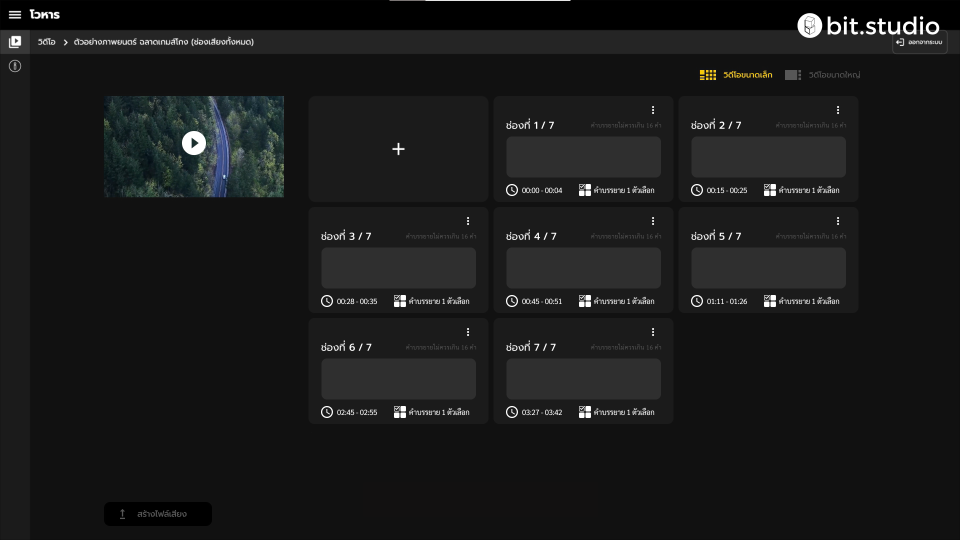
The first step is to identify the
slots where we can put the ADs in. To assist the admin, we’ve created an audio
segmentation ML model. This model detects and identifies the part of the
video that has no dialogue. It will then return the timestamp as an editable card which can be used to
fill in the AD script.
The volunteer writer enters the
VOHAN web application and selects a video from the list. When the video starts, the
writer interprets the scenes and adds the AD script simultaneously. They can come back and edit the
text anytime they want.
After AD scripts are submitted,
the admin reviews those ADs and chooses the one that is best-suited. Thanks to
a text-to-speech model embedded, the admin is able to compile the selected AD scripts
into an audio file immediately right within the web app.
Design concept and Technical
description
As crowdsourcing is the core
concept of VOHAN, we designed the web app to support users who have no or few experience in making the audio
description. VOHAN is extremely easy to access via web browser – no app download needed. The user interface (UI)
guides the user from the very beginning till the end of the video. So, people who have never known about audio
description can try making the audio description at the same time.
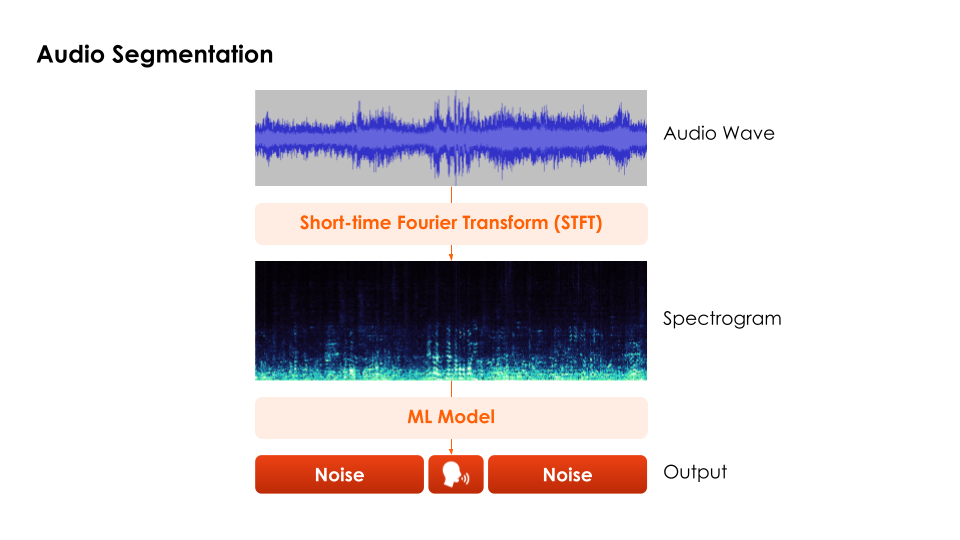
The audio segmentation has played
an important role in this project. The Audio Segmentation algorithm starts by turning an audio wave into
Spectrogram by Short-time Fourier Transform (STFT). Then our Machine learning (ML) model segments the
Spectrogram into slots where there is dialogue and no dialogue.
The challenge of this project is
to collect the dataset used to train the ML model, which has to be a clean Thai-language speech audio. Another
challenge is to design the ML model to be light enough to run on the web browser.
Conclusion
By using VOHAN as a tool, the
audio description creation would be an activity that anyone can participate in. As a result, the Pannana
application will be able to serve more content to our Thai visually impaired friends and help increase equal
access to the media, which is the basic right for everyone.